2023 iThome 鐵人賽
分享至
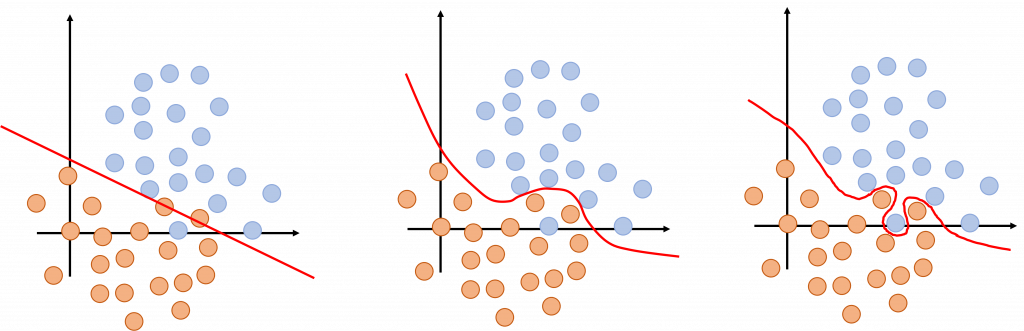
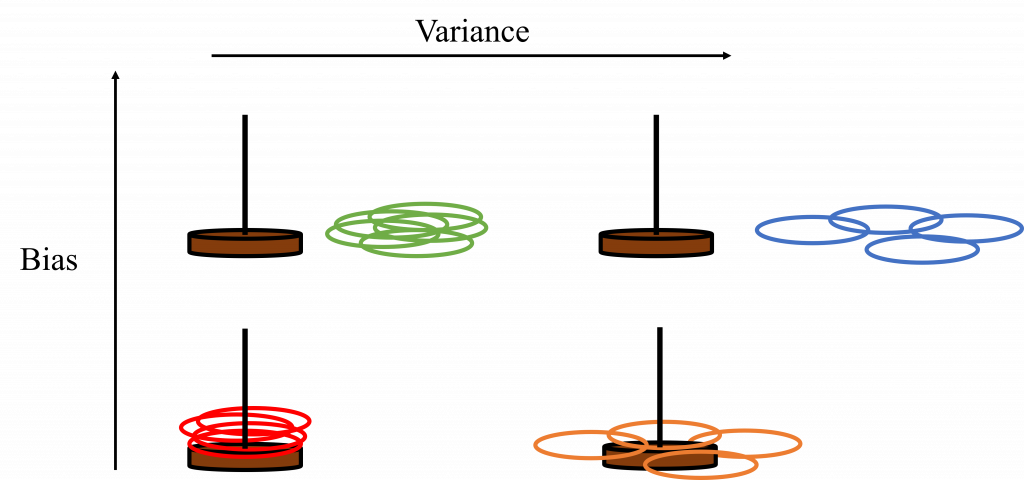
昨天的內容我們討論了AI領域中機率與統計可能會應用在哪些方面,今天我們將接著往下討論,藉由訓練資料集所訓練出來的模型,是否能在實際應用中有好的表現?
昨天的內容基本上都聚焦在機率上,不過統計在AI領域中也是非常重要的,因此,今天的內容可以看成是昨天的延伸補充,會花一些時間討論統計在AI中的應用。
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽